
New digital maps to support soil fertility management in Nepal
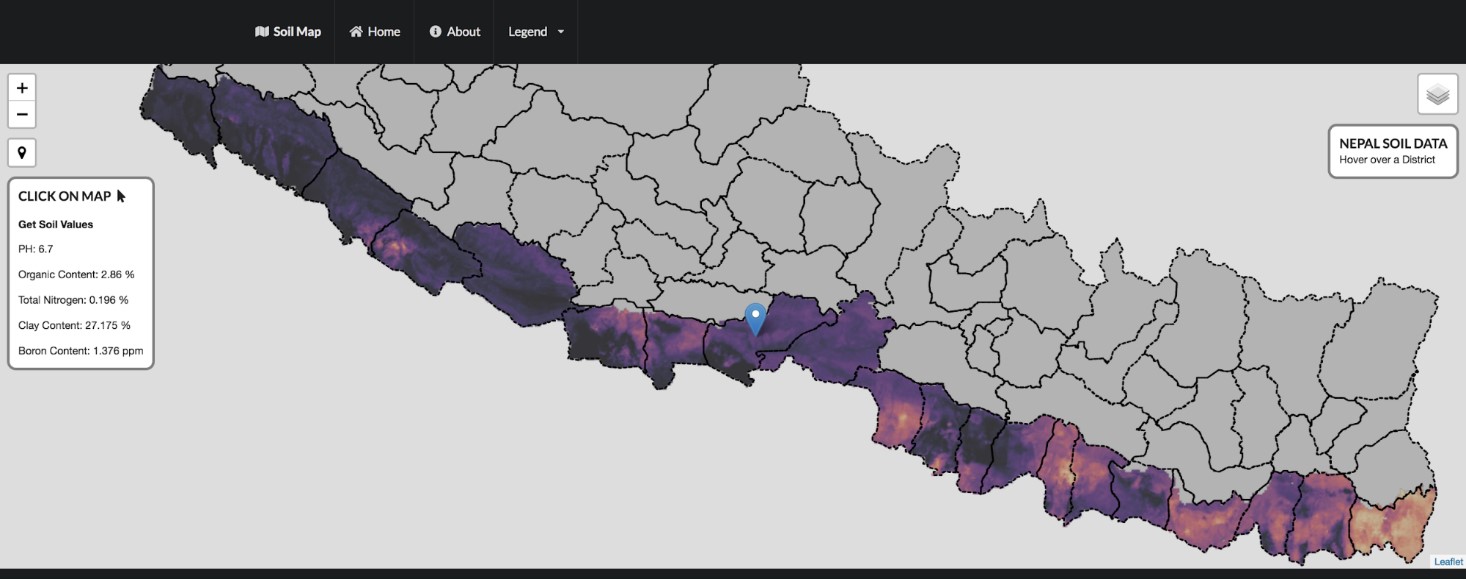 KATHMANDU, Nepal (CIMMYT) — The International Maize and Wheat Improvement Center (CIMMYT) is working with Nepal’s Soil Management Directorate and the Nepal Agricultural Research Council (NARC) to aggregate historic soil data and, for the first time in the country, produce digital soil maps. The maps include information on soil PH, organic matter, total nitrogen, clay content and boron content. Digital soil mapping gives farmers and natural resource managers easy access to location-specific information on soil properties and nutrients, so they can make efficient and localized management decisions.
KATHMANDU, Nepal (CIMMYT) — The International Maize and Wheat Improvement Center (CIMMYT) is working with Nepal’s Soil Management Directorate and the Nepal Agricultural Research Council (NARC) to aggregate historic soil data and, for the first time in the country, produce digital soil maps. The maps include information on soil PH, organic matter, total nitrogen, clay content and boron content. Digital soil mapping gives farmers and natural resource managers easy access to location-specific information on soil properties and nutrients, so they can make efficient and localized management decisions.
As part of CIMMYT’s Nepal Seed and Fertilizer (NSAF) project, researchers used new satellite imagery that enabled the resolution of the maps to be increased from 1×1 km to 250×250 m. They have updated the web portal to make it more user friendly and interactive. When loaded onto a smartphone, the map can retrieve the soil properties information from the user’s exact location if the user is within areas with data coverage. The project team is planning to produce maps for the whole country by the end of 2019.

At a World Soil Day event in Nepal, CIMMYT soil scientist David Guerena presented the new digital soil maps to scientists, academics, policymakers and other attendees. Guerena explained the role this tool can play in combatting soil fertility problems in Nepal.
These interactive digital maps are not simply visualizations. They house the data and analytics which can be used to inform site-specific integrated soil fertility management recommendations.
The first high-resolution digital soil maps for the Terai region have been produced with support from the data assets from the National Land Use Project, developed by Nepal’s Ministry of Agriculture and Livestock Development. These maps will be used to guide field programming of the NSAF project, drive the development of market-led fertilizer products, and inform and update soil management recommendations. The government of Nepal can use the same information to align policy with the needs of farmers and the capacity of local private seed and fertilizer companies.
In 2017, 16 scientists from Nepal’s Soil Management Directorate, NARC and other institutions attended an advanced digital soil mapping workshop where they learned how to use different geostatistical methods for creating soil maps. This year, as part of the NSAF project, four NARC scientists attended a soil spectroscopy training workshop and learned about digitizing soil data management and using advanced spectral methods to convert soil information into fertilizer recommendations.
Soil data matters
Soil properties have a significant influence on crop growth and the yield response to management inputs. For farmers, having access to soil information can make a big difference in the adoption of integrated soil fertility management.
Farmer motivation and decision-making relies heavily on the perceived likeliness of obtaining a profitable return at minimized risk. This largely depends on the yield response to management inputs, such as improved seeds and fertilizers, which depends to a large extent on site-specific soil properties and variation in agro-ecological conditions. Therefore, quantitative estimates of the yield response to inputs at a given location are essential for estimating the risks associated with these investments.
The digital soil maps can be accessed at https://nsafmap.github.io/.
The Nepal Seed and Fertilizer project is funded by the United States Agency for International Development (USAID) and is a flagship project in Nepal. The objective of the NSAF is to build competitive and synergistic seed and fertilizer systems for inclusive and sustainable growth in agricultural productivity, business development and income generation in Nepal.





 EL BATAN, Mexico (CIMMYT) — Modern data systems are essential to monitor, manage and plan actions taken by governments to achieve the Sustainable Development Goals (SDGs) by 2030, according to the Sustainable Development Solutions Network (SDSN), an advisory body to the United Nations Secretary General, and to the Thematic Research Network on Data and Statistics (TReENDS), an independent group of international experts working on data-related fields.
EL BATAN, Mexico (CIMMYT) — Modern data systems are essential to monitor, manage and plan actions taken by governments to achieve the Sustainable Development Goals (SDGs) by 2030, according to the Sustainable Development Solutions Network (SDSN), an advisory body to the United Nations Secretary General, and to the Thematic Research Network on Data and Statistics (TReENDS), an independent group of international experts working on data-related fields.
 Building on a more than 40-year-old partnership in crop modelling and physiology, a two-day workshop organized by CIMMYT and Australia’s
Building on a more than 40-year-old partnership in crop modelling and physiology, a two-day workshop organized by CIMMYT and Australia’s 

